


K-Means Clustering ist ein beliebter Algorithmus im Bereich des unüberwachten Lernens, der dazu verwendet wird, Daten in Gruppen oder Cluster zu unterteilen. Dieser Ansatz ermöglicht es, Muster in Daten zu erkennen, ohne dass vorherige Labels benötigt werden. Für eine Einführung in das Thema und ein unterhaltsames Brettspiel zur Veranschaulichung der Konzepte des unüberwachten Lernens findest du Informationen auf dieser Seite. Dort findest du Materialien, die dir helfen, die Grundlagen des K-Means Clustering besser zu verstehen und praktisch anzuwenden.
Schritt 1: Voraussetzungen schaffen
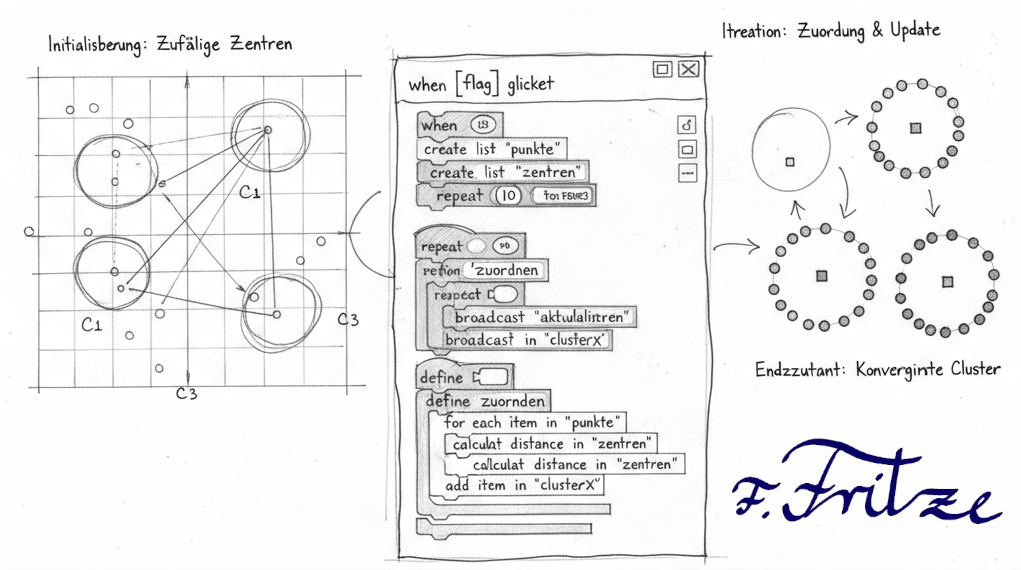
Im ersten Schritt der Entwicklung des K-Means Clustering-Programms in Scratch schaffen wir die grundlegenden Voraussetzungen für das Verfahren. Zunächst wählen wir die Anzahl der Clusterzentren, die in diesem Beispiel auf 3 festgelegt wird. Diese Entscheidung ermöglicht es uns, das Problem klein zu halten und dennoch interessante Beobachtungen zu machen.
Anschließend setzen wir die Datenpunkte, die geclustert werden sollen, zufällig auf dem Spielfeld. Idealerweise wählen wir die Zufallsbedingungen so, dass sich bereits drei lockere Gruppen bilden. Dies erleichtert das spätere Clustering und macht die Ergebnisse anschaulicher.
Nachdem die Datenpunkte platziert sind, verteilen wir die Clusterzentren zufällig auf dem Feld. Um die Visualisierung zu verbessern, verwenden wir drei verschiedene Farben für die Clusterzentren, sodass sie sich deutlich voneinander abheben. Diese Schritte legen den Grundstein für die weiteren Entwicklungen des K-Means Clustering-Algorithmus in Scratch.

Hinweis:
- Speicherung der Daten: Die Koordinaten der Punkte und Clusterzentren sowie die Färbung sollten in Listen gespeichert werden. Dies ermöglicht eine einfache Verwaltung und Aktualisierung der Daten während des Clustering-Prozesses.
- Grafische Darstellung: Die grafische Darstellung der Punkte und Clusterzentren erfolgt mittels Klonen in Scratch. Durch das Klonen können mehrere Instanzen von Objekten erstellt werden, was die Visualisierung der Cluster und deren Zentren erleichtert und eine dynamische Interaktion ermöglicht.
Diese Vorgehensweise sorgt für eine effiziente Verarbeitung und eine klare Darstellung der Ergebnisse im K-Means Clustering-Algorithmus.
Schritt 2: Zuordnung der Punkte zu den Clusterzentren
Im zweiten Schritt des K-Means Clustering-Programms kümmern wir uns um die Zuordnung der Datenpunkte zu den Clusterzentren. Sobald die Clusterzentren festgelegt sind, aktivieren wir diesen Prozess durch einen Button mit der Beschriftung „färbe“.
Wenn der „färbe“-Button gedrückt wird, erfolgt die Zuordnung der Punkte zu den nächstgelegenen Clusterzentren. Jeder Punkt wird dabei auf Basis der euklidischen Distanz zu den Clusterzentren analysiert. Der Punkt wird dem Clusterzentrum zugeordnet, das ihm am nächsten ist.
Nach der Zuordnung färben wir die Punkte entsprechend der Farbe ihres jeweiligen Clusterzentrums. Diese visuelle Darstellung hilft, die Gruppierung der Datenpunkte zu verdeutlichen und zeigt, wie die K-Means-Algorithmus funktioniert. Die Punkte, die zu einem Cluster gehören, erscheinen in der gleichen Farbe, was die Identifikation der Cluster erleichtert.
Hinweis:
- Verwendung eigener Blöcke: Die Erstellung von „eigenen Blöcken“ in Scratch hilft, den Code übersichtlicher und strukturierter zu gestalten. Dies erleichtert das Verständnis und die Wartung des Programms, insbesondere bei komplexeren Abläufen wie der Zuordnung und Färbung der Punkte.
- Färbung durch Broadcast-Nachrichten: Das Ändern der Färbung der Punkte kann durch Broadcast-Nachrichten realisiert werden. Diese Nachrichten ermöglichen es, verschiedene Teile des Programms zu synchronisieren und die Färbung der Punkte entsprechend ihrer Clusterzuordnung effizient zu aktualisieren.
Diese Tipps tragen dazu bei, die Programmierung des K-Means Clustering-Algorithmus in Scratch zu optimieren und die Benutzerfreundlichkeit zu erhöhen.
Schritt 3: Aktualisierung der Clusterzentren
Im dritten Schritt des K-Means Clustering-Programms berechnen wir die neuen Koordinaten der Clusterzentren. Dazu nehmen wir die Koordinaten der Punkte, die einem bestimmten Cluster zugeordnet sind, und bilden den Mittelwert dieser Koordinaten.
Für jedes Cluster wird der Mittelwert der x- und y-Koordinaten der zugehörigen Punkte ermittelt. Diese berechneten Werte repräsentieren die neuen Positionen der Clusterzentren und werden verwendet, um die Clusterzentren an die berechneten Koordinaten zu bewegen.
Die Aktivierung dieses Prozesses erfolgt durch den Button mit der Beschriftung „Mitteln“. Sobald dieser Button gedrückt wird, werden die neuen Clusterzentren positioniert. Danach kann die Einfärbung und der Prozess der Zuordnung der Punkte zu den Clusterzentren immer wieder wiederholt werden, bis sich die Cluster gebildet haben.
Durch diese iterative Vorgehensweise wird der Algorithmus fortlaufend optimiert, bis sich die Clusterzentren stabilisieren und die Zuordnung der Punkte nicht mehr ändert. Dieser Schritt verdeutlicht, wie der K-Means Algorithmus lernt und sich an die Struktur der Daten anpasst, um die bestmögliche Gruppierung zu erreichen.
Schreibe einen Kommentar zu