


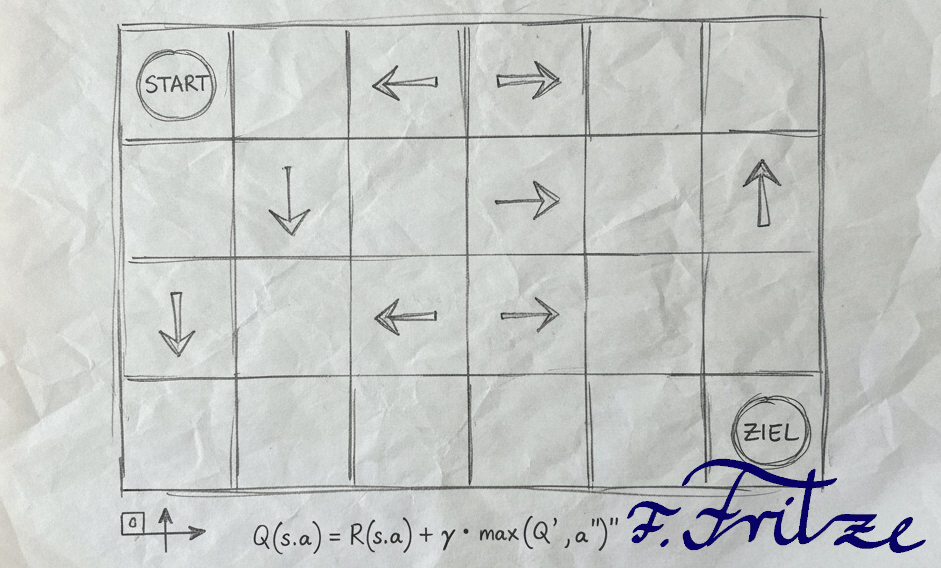
The QField serves to recreate the process of reinforcement learning with a piece of paper and a pen. This is about learning a way by using the unplugged algorithm. Unlike other algorithms that aim for optimal solutions, this approach focuses on learning through trial and feedback.
Preparation
Print out the picture or draw it (instead of Scratch you can also write 'Start' in the first field and instead of the pie 'Goal'). You also need a piece of play (as with humans, don't get angry).
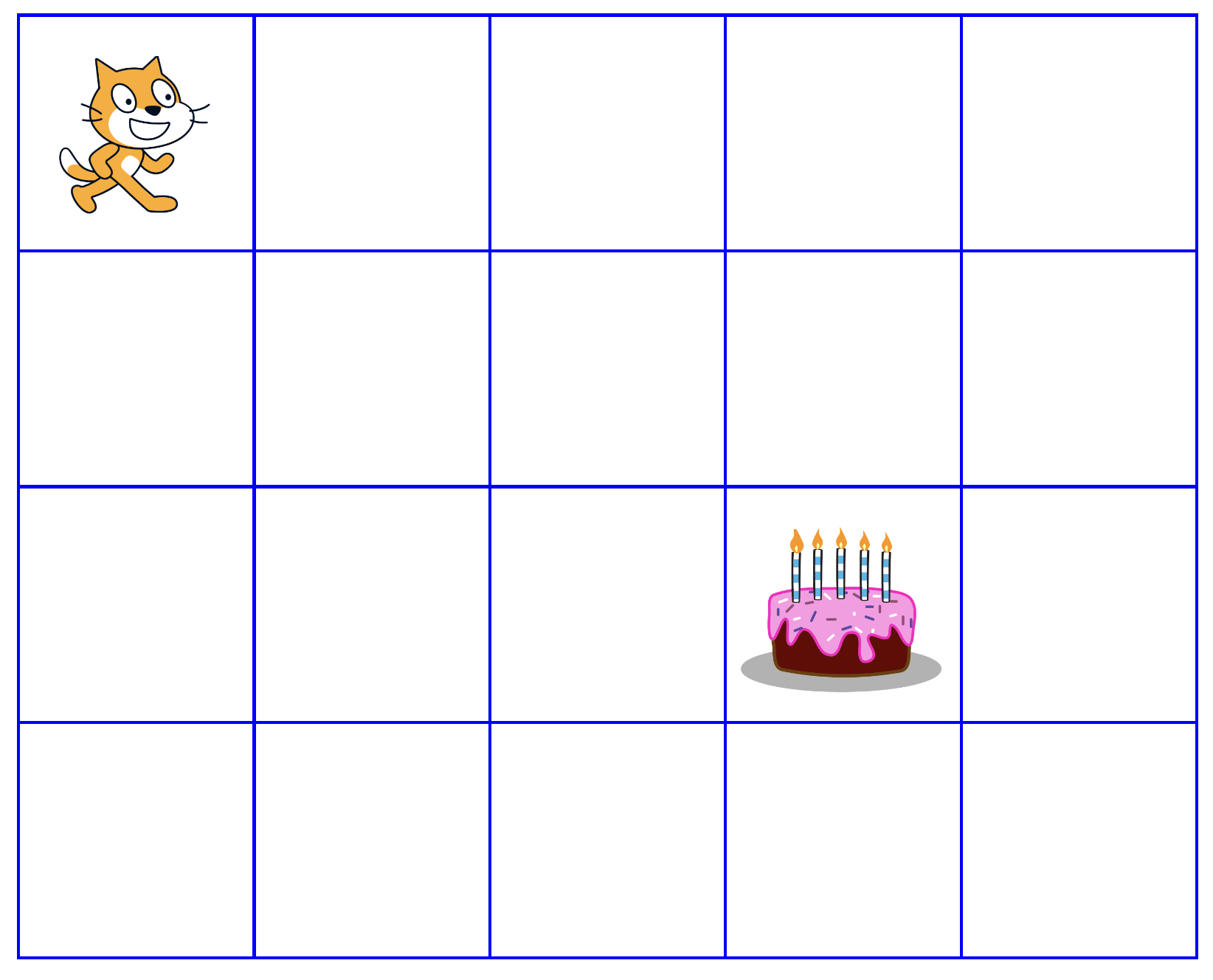
Scratch first moves randomly across the field.
The small scratch program shows you the direction in which you drag your figure (if possible), click on the green flag or directly on the arrow.
Scratch learns
Our agent Scratch initially has no way to know the next step, so he happens to run across the field.
However, Scratch knows its goal. When he reaches his goal, he can draw an arrow in the direction of running into the field from which he came. At the next pass he is now a little bit smarter.
Of course, Scratch now knows where to go as soon as he hits an arrow. Therefore, as soon as he meets an arrow, he can draw an arrow in the direction of running into the field from which he came. He can then follow the arrow on which he stands.
For detailed instructions on developing with Scratch, check out the follow-up post Q-Learning Entwicklung mit Scratch an.
Did you find a way?
Look at the drawn article image above again. What could be wrong there?
You've probably noticed that Scratch wanted to run out of the field at the same place several times. How can you improve the process so that Scratch adjusts his behavior?
Make the field more interesting, build in obstacles or give the card a different shape.
Reinforcement learning is a learning approach in which an agent learns to improve his decisions through interactions with his environment. In this case, it is used to allow Scratch to learn how to reach his target through random movements and drawing arrows.
What feedback does Scratch get from his environment to learn?
Where could reinforcement learning be used in other scenarios or applications?
Leave a Reply